
Últimamente circula una idea por LinkedIn, X y un par de hilos de Hacker News que conviene mirar con calma: que los LLM modernos —Claude en particular— ya no necesitan Markdown para ser eficientes, que mandar HTML «es más elegante», queda más bonito por pantalla, y que el modelo internamente «limpia el ruido» y termina consumiendo prácticamente los mismos tokens. La conclusión que se vende es tentadora: HTML gratis, mejor presentación, mismo coste.
No es así. Y como casi todo en este oficio, lo razonable no es opinar, sino medirlo.
De dónde viene esto
El origen del debate es real y serio. El 8 de mayo de 2026, Thariq Shihipar, engineering lead de Claude Code en Anthropic, publicó un artículo viral llamado «Using Claude Code: The Unreasonable Effectiveness of HTML». Su argumento, resumido sin caricaturas, es que para outputs destinados a humanos (planes de proyecto, code reviews, comparativas visuales, dashboards efímeros) HTML aporta densidad informativa, color, tablas con jerarquía, SVG inline e interactividad que Markdown no puede dar. Y eso, dice, justifica el sobrecoste.
Hasta ahí, opinión legítima sobre experiencia de usuario.
El problema empieza cuando ese argumento se simplifica en el camino y acaba como «Claude ya consume los mismos tokens con HTML que con Markdown». Eso es lo que se ha colado en muchos hilos, y eso es lo que es técnicamente falso.
La medición, antes que la teoría
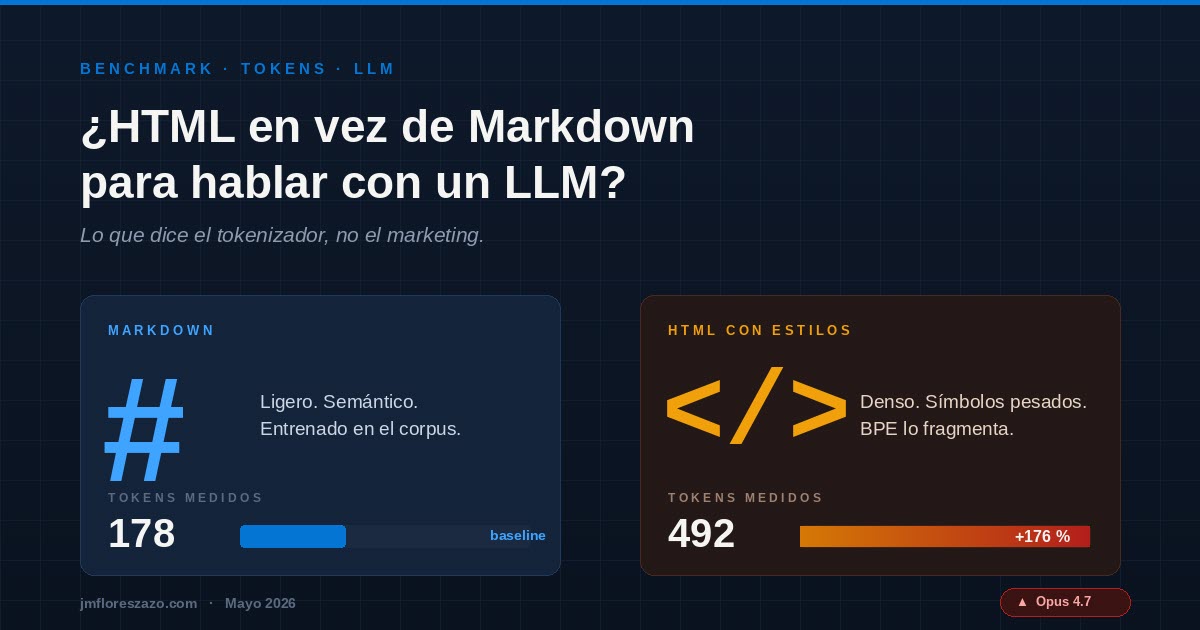
Tomé un fragmento idéntico (una intro corta a Azure Functions, ~700 caracteres de contenido real) y lo serialicé en tres formatos. Tokenización con regex GPT-2 + estimación BPE; el número absoluto puede variar según el tokenizador exacto, pero el ratio entre formatos es robusto.
| Formato | Caracteres | Tokens estimados | vs Markdown |
|---|---|---|---|
| Markdown | 711 | 178 | — |
HTML «limpio» (<h1>, <ul>, <p>) |
902 | 273 | +53% |
HTML con <style> inline |
1.624 | 492 | +176% |
Estos números no son una sorpresa ni un invento mío:
- Web2MD publicó un benchmark sobre artículos web reales: un texto que ocupa ~2.800 tokens en Markdown sube a ~8.000 en HTML. Reducción del 67% al pasar HTML → Markdown.
- Sobre 200 páginas mixtas (docs, blogs, Wikipedia, noticias), la conversión a Markdown supone una reducción media del 87,5% en tokens.
- El propio Thariq lo admite en su post: el HTML limpio cuesta 2-3x más tokens que el Markdown equivalente, y HTML con CSS y JS reales puede llegar a 8-10x.
Es decir, el debate honesto no es «¿HTML cuesta lo mismo?». El debate es: «¿compensa pagar entre 2x y 10x más tokens a cambio de mejor experiencia visual?». Y la respuesta depende del caso.
Por qué la frase «Claude limpia todo y consume lo mismo» no se sostiene
Tres razones técnicas, ordenadas:
1. El modelo no controla los tokens que genera. Cuando un LLM produce su respuesta, cada <h2>, cada class="...", cada </div> pasa por el tokenizador exactamente igual que el contenido. No existe un paso oculto de compresión semántica entre lo que el modelo escribe y lo que se factura. Lo que sale es lo que se cuenta.
2. BPE no está optimizado para markup. Los tokenizadores BPE (cl100k, el de Claude, los de la familia GPT) están entrenados predominantemente sobre prosa y código. Símbolos densos como <, >, /, ="..." suelen partirse en varios tokens. Markdown, al usar caracteres ligeros (#, -, **, ```) consume menos. No es opinión, es cómo está entrenado el vocabulario.
3. «Limpiar el HTML antes de enviarlo» es input, no output. Sí existe una pipeline legítima web → Markdown → modelo, y es lo que hacen herramientas tipo Jina Reader, Trafilatura o Web2MD. Pero esa pipeline confirma exactamente lo contrario del bulo: el ahorro está en convertir a Markdown, no en mandar HTML «limpio».
Donde quizá nace la confusión: caching ≠ menos tokens
Anthropic, OpenAI y otros proveedores ofrecen prompt caching: si reenvías el mismo prefijo de contexto, el coste por token cacheado es menor. Esto reduce el coste en € por token, pero no el número de tokens consumidos. Son dos métricas distintas y se mezclan a menudo en los hilos divulgativos. Si alguien ha medido el gasto en factura y ha visto bajada, probablemente está viendo efecto del caché, no eficiencia del formato.
Calidad del output, no solo coste
Más allá del recibo, el formato afecta a la calidad de las respuestas. Benchmark de Web2MD con el mismo contenido en ambos formatos sobre GPT-4, Claude y Gemini:
| Tarea | HTML input | Markdown input | Mejora |
|---|---|---|---|
| Resumen | 6.8 | 8.9 | +31% |
| Q&A (precisión) | 7.1 | 8.7 | +23% |
| Extracción de puntos clave | 6.5 | 9.1 | +40% |
| Traducción | 7.8 | 8.4 | +8% |
| Reescritura de contenido | 6.2 | 8.6 | +39% |
En tablas, las representaciones Markdown superan a las HTML en precisión de extracción (60,7% vs 53,6% en evaluaciones sobre GPT). Lógica detrás de esto: el corpus de entrenamiento contiene una cantidad gigantesca de Markdown bien formado (README, wikis, docs), y muy poco HTML bien estructurado y libre de ruido.
¿Y con Claude Opus 4.7? Spoiler: peor
La objeción razonable es legítima: «los benchmarks que citas son sobre GPT-4 o Claude 3.5, modelos de hace un año. ¿Sigue siendo válido con Opus 4.7?». La respuesta corta es sí, y además el problema se agrava. Veamos los datos publicados desde el lanzamiento.
Opus 4.7 estrena tokenizer nuevo, y eso cambia el escenario por completo. La propia documentación de Anthropic lo dice sin maquillaje: «This new tokenizer may use roughly 1x to 1.35x as many tokens when processing text compared to previous models (up to ~35% more, varying by content)». Es decir, el mismo texto que en Opus 4.6 ocupaba 100 tokens, en 4.7 puede ocupar hasta 135. Mismo precio por token, mismo cupo en el plan, pero más tokens por prompt.
Los números medidos en producción son aún peores que la horquilla oficial:
| Fuente | Workload | Inflación medida vs 4.6 |
|---|---|---|
| Anthropic (docs oficiales) | Genérico | 1.0x – 1.35x |
| Claude Code Camp (medición) | Docs técnicos | 1.47x |
| Claude Code Camp (medición) | CLAUDE.md real |
1.45x |
| Simon Willison | System prompt de Opus 4.7 | 1.46x |
| OpenRouter (cohorte de migración) | Prompts <10K tokens | 1.42x – 1.45x |
| OpenRouter (cohorte de migración) | Prompts ≥10K tokens | 1.32x – 1.34x |
| Korchasa (análisis multi-lenguaje) | Prosa inglés | +31% |
| Korchasa (análisis multi-lenguaje) | Código fuente | +22% |
| Korchasa (análisis multi-lenguaje) | Markdown | +21% |
| Korchasa (análisis multi-lenguaje) | Identificadores camelCase | +51% |
El análisis de Korchasa sobre 53 idiomas y 12 tipos de datos identifica el motivo: en 4.7 se han eliminado del vocabulario las cadenas largas de palabras inglesas pre-mergeadas (BPE merges) que tenía 4.6. Ahora el modelo necesita varios tokens cortos donde antes usaba uno largo. JSON, espacios en blanco y dígitos no cambian; lenguajes no latinos (CJK, árabe, hebreo, hindi, ruso) tampoco. Lo que se ha pagado son las palabras inglesas, que es justo el tipo de contenido que llena un CLAUDE.md, un system prompt o un payload HTML.
Por qué esto amplifica el problema con HTML
Aquí está la conexión con el debate del artículo. Si el tokenizer de 4.7 fragmenta más cualquier texto inglés, fragmenta todavía más el markup HTML, que ya partía con desventaja en BPE por sus símbolos densos (<, >, /, ="..."). El gap entre Markdown y HTML, lejos de cerrarse con el «modelo más nuevo y más inteligente», se ensancha:
- En Opus 4.6, HTML semántico limpio costaba ~1.5x más tokens que su equivalente Markdown.
- En Opus 4.7, esa misma penalización se compone con la inflación general del nuevo tokenizer (1.3x – 1.45x), porque los símbolos del markup están entre lo que peor encaja con un vocabulario al que le han quitado merges largos.
OpenRouter, midiendo cohortes reales de usuarios que migraron 4.6 → 4.7, reporta incrementos de coste del 12% al 27% en producción después del descuento del 90% por caching. Sin caching, la inflación de tokens es del 32% al 45% sobre prompts y completaciones.
Lectura operativa
Esto refuerza, no debilita, el argumento del artículo:
- Si ya estabas dudando entre MD y HTML para input a Claude, en 4.7 la balanza se inclina aún más hacia Markdown. El sobrecoste de HTML se multiplica por la inflación base del nuevo tokenizer.
- Si tienes pipelines en producción, replay obligatorio antes de migrar 4.6 → 4.7. La factura no se mantiene aunque el rate card sí: la documentación oficial avisa de que
count_tokensdevolverá números distintos para el mismo contenido. - El caching sigue siendo la palanca principal de coste. El 90% de descuento por cache hit se mantiene en 4.7, pero el prefijo que escribes al caché es 1.3x – 1.45x más grande la primera vez. Es decir, el cold-start es más caro, aunque el régimen estacionario apenas se note.
- camelCase paga +51% de inflación. Si tu RAG corporativo serializa nombres de variables, identificadores Java/C#, paths de Azure (
Microsoft.Storage/storageAccounts), o cualquier código fuente sin formato, ese 51% va directo a tu factura. Es otro argumento para limpiar el input antes de mandarlo, no para meter HTML.
Resumido: el tokenizador nuevo de Opus 4.7 mejora cosas (multilenguaje no latino, soporte de imágenes a alta resolución, instruction-following estricto en +5pp según IFEval), pero no resuelve la economía del formato. Si acaso, la acentúa. El consejo no cambia: mide con el count_tokens oficial del modelo concreto que vas a usar, no con heurísticas de hace un año.
Cuándo cada uno
Sin dogmatismo. Cada formato tiene su sitio:
Markdown es la elección por defecto cuando:
- Cargas contexto al modelo (RAG, ingestión de documentación, system prompts largos).
- El output va a otro paso de la pipeline (parser, embedding, log estructurado, otro agente).
- El artefacto vive en Git y necesita diffs legibles en pull requests.
- Estás en un escenario de alto throughput donde el coste por output domina.
HTML puede compensar cuando:
- El consumidor final es un humano que va a leer el artefacto una sola vez.
- Necesitas densidad visual: tablas con color, SVG inline, badges, jerarquía clara.
- Estás en Claude Artifacts o un canvas donde el render aporta valor real.
- Aceptas pagar 2-3x tokens a cambio de mejor cognición humana, y lo presupuestas.
Resumido en una frase: si el lector es un modelo, Markdown. Si el lector es un humano que va a leerlo una vez, HTML puede compensar.
Aterrizando en arquitectura enterprise
En los escenarios que tocamos a diario —MCP en .NET y Azure, AI Gateway sobre YARP, agentes orquestados, RAG corporativo, control plane de IA con APIM— el flujo dominante es modelo dentro de pipeline, no «informe bonito para enseñar a un cliente». En ese terreno, mandar HTML para hablar con el LLM es regalar tokens sin contrapartida.
Y en gobierno de coste de IA empresarial, esa diferencia no es cosmética: a 1.000 páginas al mes a precios actuales de Claude Sonnet, el sobrecoste por usar HTML en lugar de Markdown en la entrada se mueve en el orden de cientos de euros por pipeline. Con Opus 4.7 el cálculo es aún más sangrante: multiplica ese sobrecoste por la inflación del nuevo tokenizer y multiplícalo por número de pipelines y por entornos (dev, staging, prod). En cualquier organización con varios casos de uso en producción, esto se nota en el FinOps mensual.
No soy el único que lo ve así
Scott S. Nelson, en Markup is the New Markdown (12 mayo 2026), pone el dedo en la llaga del propio fenómeno viral:
«Que se haya viralizado así dice menos del artículo en sí y más de las ganas que tenía la gente de que alguien les diera permiso para hacer lo que ya querían hacer.»
En el original: «The fact that it spread the way it did says less about the content and more about how hungry people are for permission to do the thing they already half-wanted to do.»
Es exactamente lo que ha pasado. El post de Thariq es legítimo en su acotación original —output destinado a humanos, no input a modelos— pero la versión que circula por LinkedIn ha perdido toda esa precisión por el camino. Y eso, en enterprise, cuesta dinero.
Conclusión
La intuición correcta es la que muchos teníamos: no, HTML no consume los mismos tokens que Markdown, ni se «limpia mágicamente» por el modelo ni por la tool que el modelo usa. El argumento real de Thariq es legítimo, pero acotado: pagas más tokens a cambio de mejor experiencia humana, en outputs concretos, no como regla general.
Y con Opus 4.7, el argumento se refuerza en lugar de debilitarse. El nuevo tokenizer infla todo el texto inglés entre un 30% y un 45% real medido en producción, lo que amplifica la penalización del markup denso del HTML en lugar de mitigarla. Quien esperaba que «los modelos nuevos resuelvan el problema del formato» se ha llevado lo contrario: un tokenizer que paga más por palabra y, por composición, más todavía por etiqueta.
Para input al modelo y para flujos agente-a-agente, Markdown sigue siendo objetivamente la elección correcta en 2026. Y la única forma honesta de zanjar el debate en cada caso no es leer hilos, es medir tokens con el tokenizador del modelo concreto que usas.
Antes de cambiar el formato por defecto de tu stack, pasa tu contenido real por count_tokens de Anthropic (o tiktoken de OpenAI) especificando el modelo destino, no el genérico. Probablemente te llevarás la misma sorpresa que me llevé yo.
Enlaces y referencias
El debate original
- Galería oficial de Thariq Shihipar (20 ejemplos HTML generados por Claude Code) https://thariqs.github.io/html-effectiveness
- Simon Willison — cobertura del post de Thariq (fecha de referencia: 8 mayo 2026) https://simonwillison.net/2026/May/8/unreasonable-effectiveness-of-html/
- Scott S. Nelson — Markup is the New Markdown (réplica matizada, 12 mayo 2026) https://theitsolutionist.com/2026/05/12/markup-is-the-new-markdown/
- Kurtis Redux — The Unreasonable Ineffectiveness of HTML (contraréplica directa) https://kurtis-redux.medium.com/the-unreasonable-ineffectiveness-of-html-5bd01ae1e879
Datos empíricos sobre tokens, Markdown y HTML
- Web2MD — Markdown vs HTML para LLM (benchmark de calidad por tarea) https://web2md.org/blog/markdown-vs-html-for-llm
- Web2MD — Guía práctica para reducir consumo de tokens (reducción media del 87,5%) https://web2md.org/blog/reduce-llm-token-usage-practical-guide
- Beam.ai — HTML vs Markdown for AI Agents: Which Format Wins in 2026 https://beam.ai/agentic-insights/html-vs-markdown-which-format-actually-makes-ai-agents-more-useful
- ReleasePad — The Optimal Format for LLM Content Ingestion https://www.releasepad.io/blog/html-vs-markdown-the-optimal-format-for-llm-content-ingestion/
- SearchCans — Markdown vs HTML for LLM Context Optimization https://www.searchcans.com/blog/markdown-vs-html-llm-context-optimization-2026/
Datos específicos del tokenizer de Opus 4.7
- Anthropic — What’s new in Claude Opus 4.7 (documentación oficial: 1.0x – 1.35x) https://platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7
- Simon Willison — Claude Token Counter con comparativa 4.6 vs 4.7 (medido: 1.46x) https://simonwillison.net/2026/apr/20/claude-token-counts/
- Claude Code Camp — I Measured Claude 4.7’s New Tokenizer (medido: 1.45x – 1.47x) https://www.claudecodecamp.com/p/i-measured-claude-4-7-s-new-tokenizer-here-s-what-it-costs-you
- OpenRouter — Opus 4.7’s New Tokenizer: What It Actually Costs (cohorte real de migración) https://openrouter.ai/announcements/opus-47-tokenizer-analysis
- Korchasa — opus 4.7: tokenizer changes and rising costs (análisis sobre 53 idiomas y 12 tipos de datos) https://korchasa.dev/posts/2026_04_17_opus_4_7_tokenizer/
- Finout — Claude Opus 4.7 Pricing: The Real Cost Story (análisis FinOps del impacto real) https://www.finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag
Herramientas para medir tú mismo
- Anthropic — Endpoint oficial
count_tokens(gratuito, sin inferencia) https://docs.claude.com/en/api/messages-count-tokens - OpenAI —
tiktoken(proxy razonable para BPE genérico) https://github.com/openai/tiktoken - Token Calculator multi-modelo (GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro) https://token-calculator.net/



